Elan
 Elan
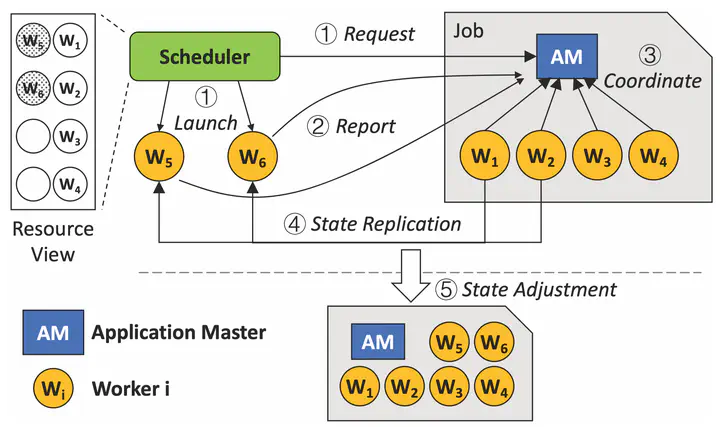
ElanShowing a promising future in improving resource utilization and accelerating training, elastic deep learning training has been attracting more and more attention recently. Nevertheless, existing approaches to provide elasticity have certain limitations. They either fail to fully explore the parallelism of deep learning training when scaling out or lack an efficient mechanism to replicate training states among different devices.
To address these limitations, we design Elan, a generic and efficient elastic training system for deep learning. In Elan, we propose a novel hybrid scaling mechanism to make a good trade-off between training efficiency and model performance when exploring more parallelism. We exploit the topology of underlying devices to perform concurrent and IO-free training state replication. To avoid the high overhead of start and initialization, we further propose an asynchronous coordination mechanism. Powered by the above innovations, Elan can provide high-performance (∼1s) migration, scaling in and scaling out support with negligible runtime overhead (<3‰). For elastic training of ResNet-50 on ImageNet, Elan improves the time to solution by 20%. For elastic scheduling, with the help of Elan, resource utilization is improved by 21%+ and job pending time is reduced by 43%+.