HypeReca
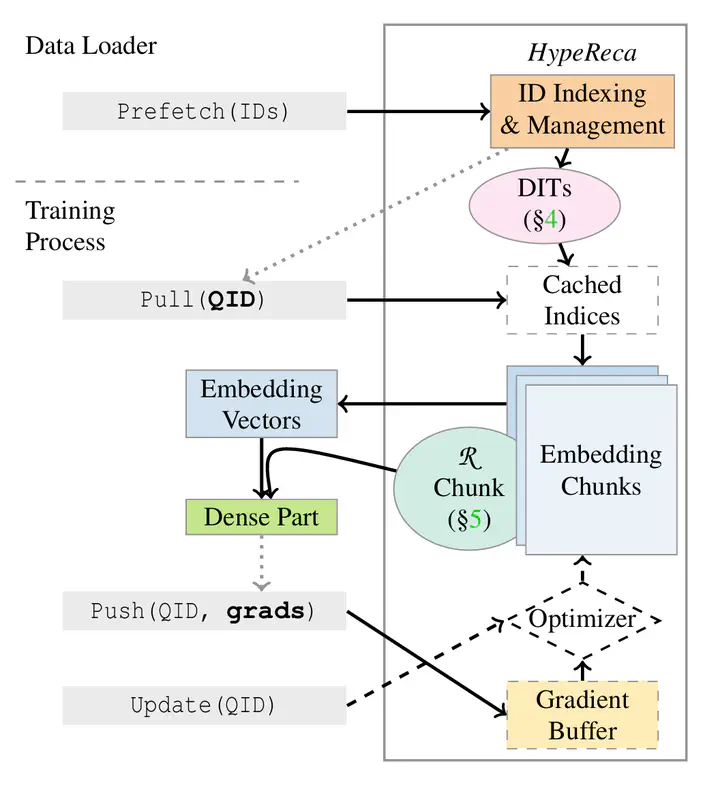 Overview of HypeReca
Overview of HypeReca
Making high-quality recommendations is important in online applications. To improve user satisfaction and effectiveness of advertising, deep learning-based recommendermodels (DLRM) are widely studied and deployed. Training these models on massive data demands increasing computation power, commonly provided by a cluster of numerous GPUs. Meanwhile, the embedding tables of the models arehuge, posing challenges on the memory. Existing systems exploit host memory and hashing techniques to accommodate them. However, the simple offloading design is hard to scaleup to multiple nodes. The sparse access to the distributed embedding tables introduces high data management and all-to-allcommunication overhead.
We find that a distributed in-memory key-value databaseis the best abstraction to serve and maintain embeddingvectors in DLRM training. To achieve high scalability, our system, HypeReca, utilizes both GPU and CPU memory. We improve the throughput of data management according to the batching pattern of DNN training, using apipeline over decentralized indexing tables and a contention-avoiding schedule for data exchange. A two-fold parallelstrategy is used to guarantee consistency of all embedding vectors. The communication overhead is reduced by replicating a few frequently accessed embedding vectors, exploiting the sparse pattern with a performance model. In our evaluation on 32 GPUs over real-world datasets, HypeReca achieves 2.16−16.8× end-to-end speedup over HugeCTR, TorchRec and TFDE.