 SmartMoE Overview
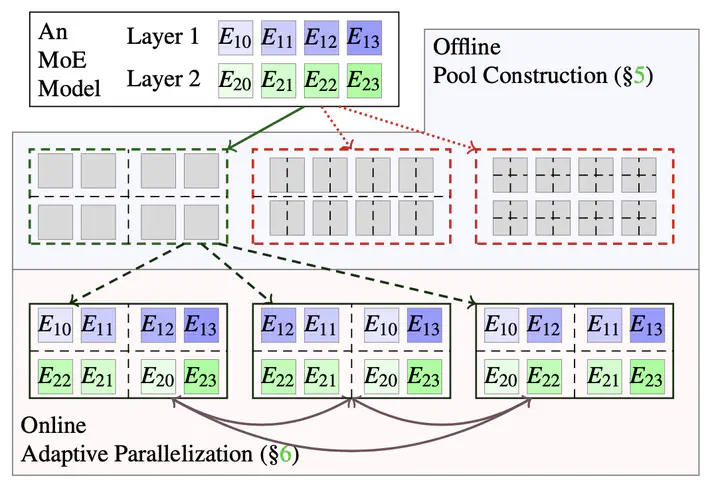
SmartMoE OverviewDeep neural networks are growing large for stronger model ability, consuming enormous computation resources to train them. Sparsely activated models have been increasingly proposed and deployed to reduce training costs while enlarging model size. Unfortunately, previous auto-parallelization approaches designed for dense neural networks can hardly be applied to these sparse models, as sparse models are data- sensitive and barely considered by prior works. To address these challenges, we propose SmartMoE to perform distributed training for sparsely activated models automatically. We find optimization opportunities in an enlarged space of hybrid parallelism, considering the workload of data-sensitive models. The space is decomposed into static pools offline, and choices to pick within a pool online. To construct an optimal pool ahead of training, we introduce a data-sensitive predicting method for performance modeling. Dynamic runtime selection of optimal parallel strategy is enabled by our efficient searching algorithm. We evaluate SmartMoE on three platforms with up to 64 GPUs. It achieves up to 1.88× speedup in end-to-end training over the state-of-the-art MoE model training system FasterMoE. You can find it at https://github.com/zms1999/SmartMoE