*
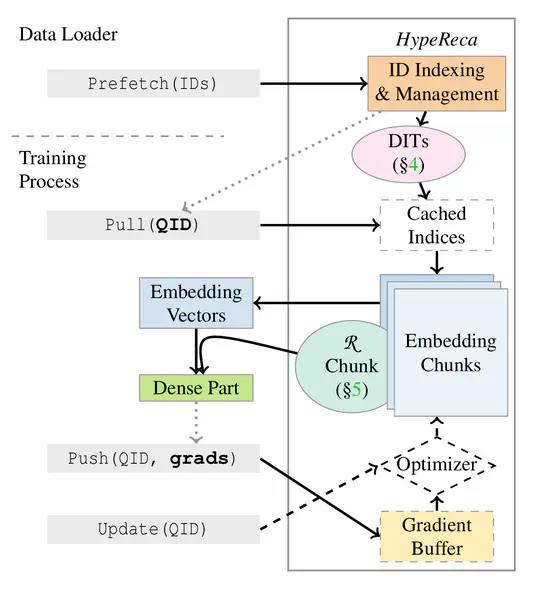


Making high-quality recommendations is important in online applications. To improve user satisfaction and effectiveness of advertising, deep learning-based recommendermodels (DLRM) are widely studied and deployed. Training these models on massive data demands increasing computation power, commonly provided by a cluster of numerous GPUs.
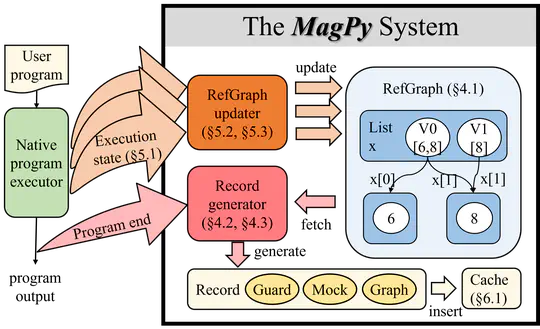
Real-world deep learning programs are often developed with dynamic programming languages like Python, which usually have complex features, such as built-in functions and dynamic typing. These programs typically execute in eager mode, where tensor operators run without compilation, resulting in poor performance.
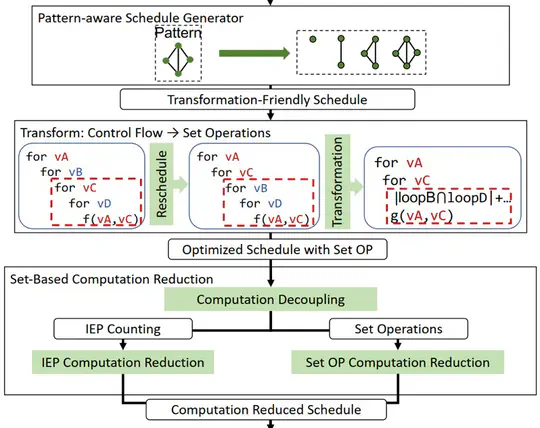
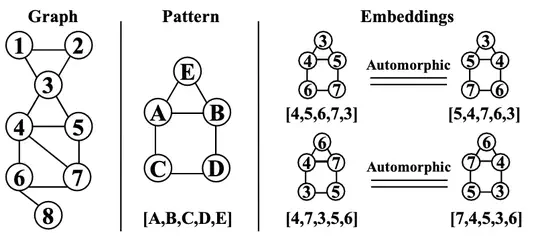
GraphSet is a pattern-aware graph mining system supporting both CPU and GPU. GraphSet achieves high performance by proposing a set-based equivalent transformation approach to optimize pattern-aware graph mining applications, which can leverage classic set properties to eliminate most control flows and reduce computation overhead exponentially.
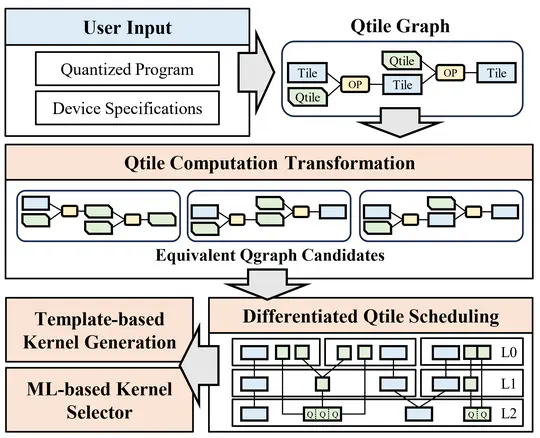
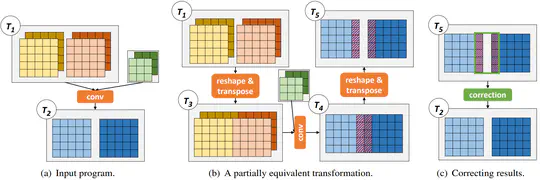
Boosting the execution performance of deep neural networks (DNNs) is critical due to their wide adoption in real-world applications. However, existing approaches to optimizing the tensor computation of DNNs only consider transformations representable by a fixed set of predefined tensor operators, resulting in a highly restricted optimization space.
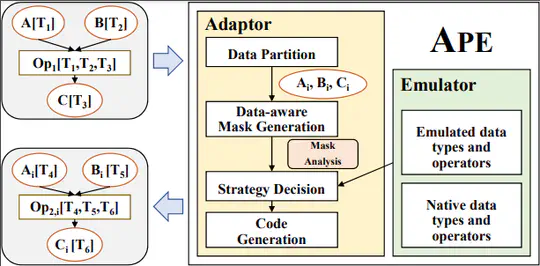
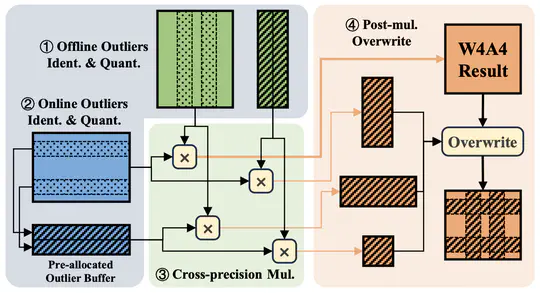
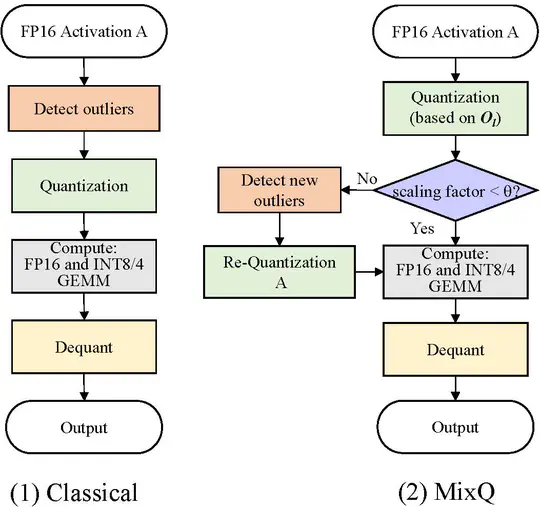
Domain-Specific Accelerators (DSAs) are being rapidly developed to support high-performance domain-specific computation. Although DSAs provide massive computation capability, they often only support limited native data types. To mitigate this problem, previous works have explored software emulation for certain data types, which provides some compensation for hardware limitations.
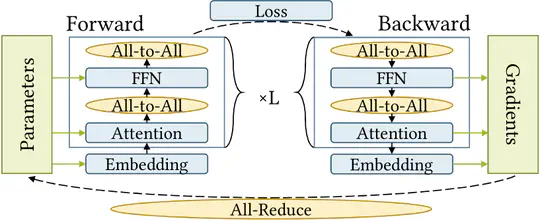
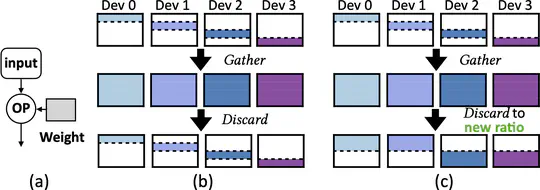
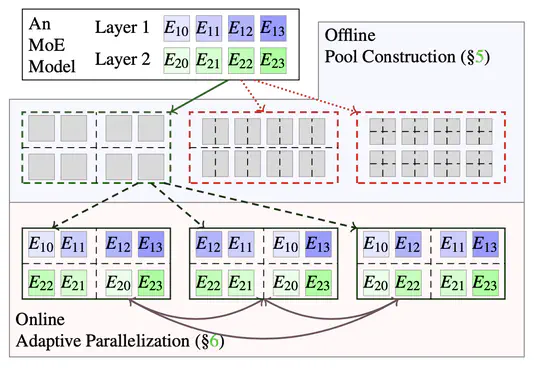
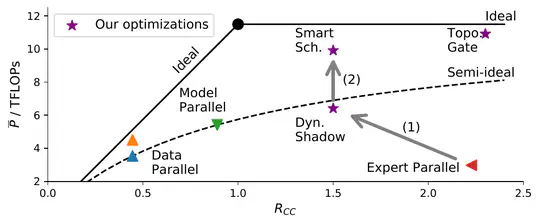
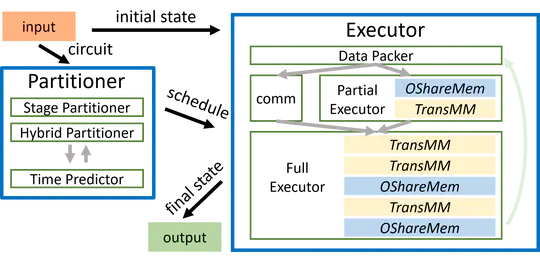
Large-scale pretrained AI models have shown state-of-the-art accuracy in a series of important applications. As the size of pretrained AI models grows dramatically each year in an effort to achieve higher accuracy, training such models requires massive computing and memory capabilities, which accelerates the convergence of AI and HPC.
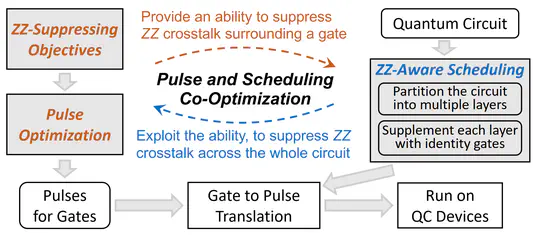
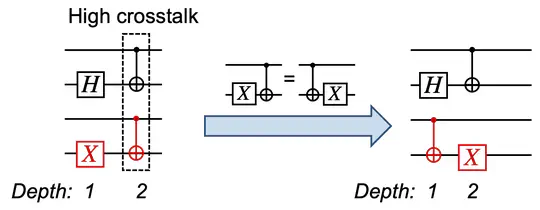
Noise is a significant obstacle to quantum computing, and ZZ crosstalk is one of the most destructive types of noise affecting superconducting qubits. Previous approaches to suppressing ZZ crosstalk have mainly relied on specific chip design that can complicate chip fabrication and aggravate decoherence.
Crosstalk is one of the major types of noise in quantum computers. To design high-fidelity quantum gates and large-scale quantum computers, effectively suppressing crosstalk is becoming increasingly important. Previous approaches to mitigate crosstalk rely on either hardware strategies, which are only applicable on limited platforms, or software techniques, which, however, cannot fully explore instruction parallelism.

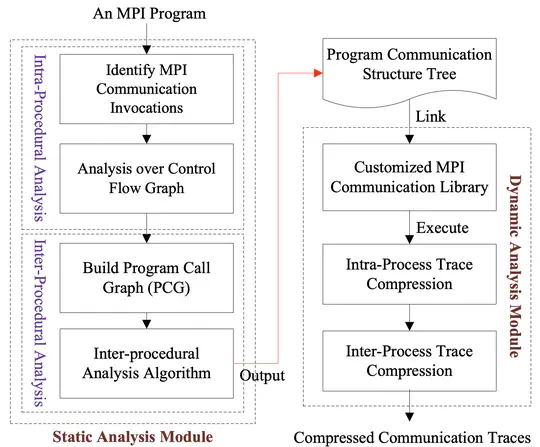
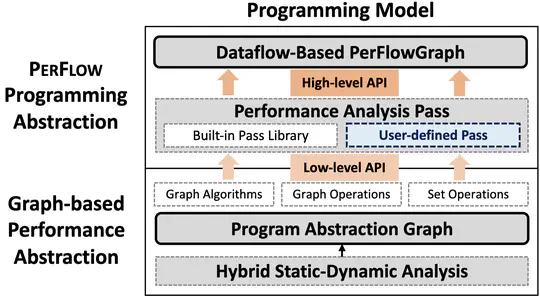
Communication traces are increasingly important, both for parallel applications’ performance analysis/optimization, and for designing next-generation HPC systems. Meanwhile, the problem size and the execution scale on supercomputers keep growing, producing prohibitive volume of communication traces.
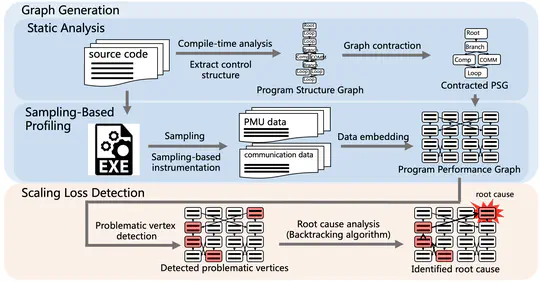
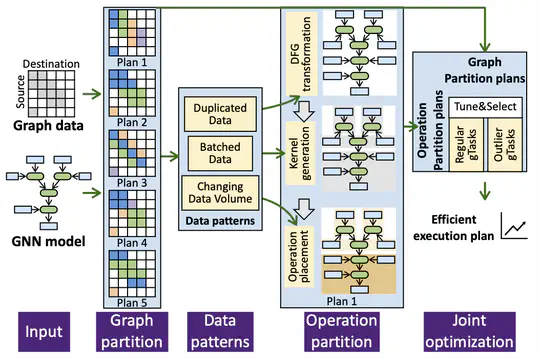
Graph Neural Network (GNN) has recently drawn a rapid increase of interest in many domains for its effectiveness in learning over graphs. Maximizing its performance is essential for many tasks, but remains preliminarily understood.


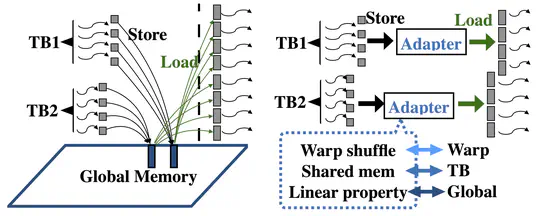
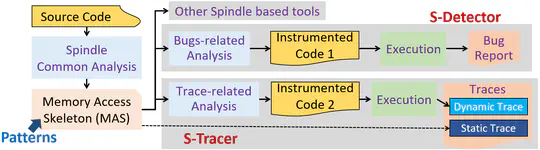
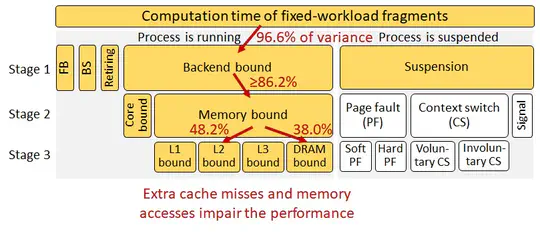
Memory monitoring is of critical use in understanding applications and evaluating systems. Due to the dynamic nature in programs’ memory accesses, common practice today leaves large amounts of address examination and data recording at runtime, at the cost of substantial performance overhead (and large storage time/space consumption if memory traces are collected).
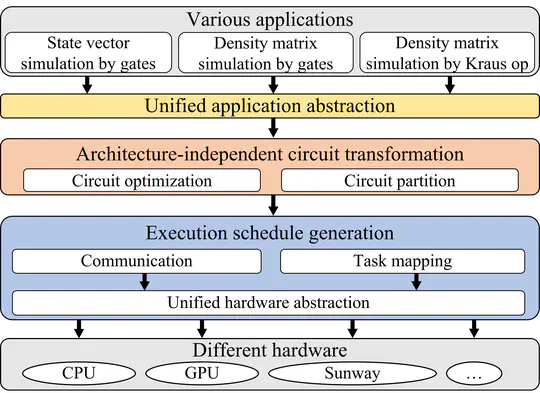
Quantum circuit simulation is critical for verifying quantum computers. Given exponential complexity in the simulation, existing simulators use different architectures to accelerate the simulation. However, due to the variety of both simulation methods and modern architectures, it is challenging to design a high-performance yet portable simulator.